TL;DR We extend the domain-tuning encoder approach (E4T) to multiple-domains.
Multi-Domain Fast tuning Single-shot
Text-to-image (T2I) personalization allows users to guide the creative image generation process by combining their own visual concepts in natural language prompts. Recently, encoder-based techniques have emerged as a new effective approach for T2I personalization, reducing the need for multiple images and long training times. However, most existing encoders are limited to a single-class domain, which hinders their ability to handle diverse concepts. In this work, we propose a domain-agnostic method that does not require any specialized dataset or prior information about the personalized concepts. We introduce a novel contrastive-based regularization technique to maintain high fidelity to the target concept characteristics while keeping the predicted embeddings close to editable regions of the latent space, by pushing the predicted tokens toward their nearest existing CLIP tokens. Our experimental results demonstrate the effectiveness of our approach and show how the learned tokens are more semantic than tokens predicted by unregularized models. This leads to a better representation that achieves state-of-the-art performance while being more flexible than previous methods.
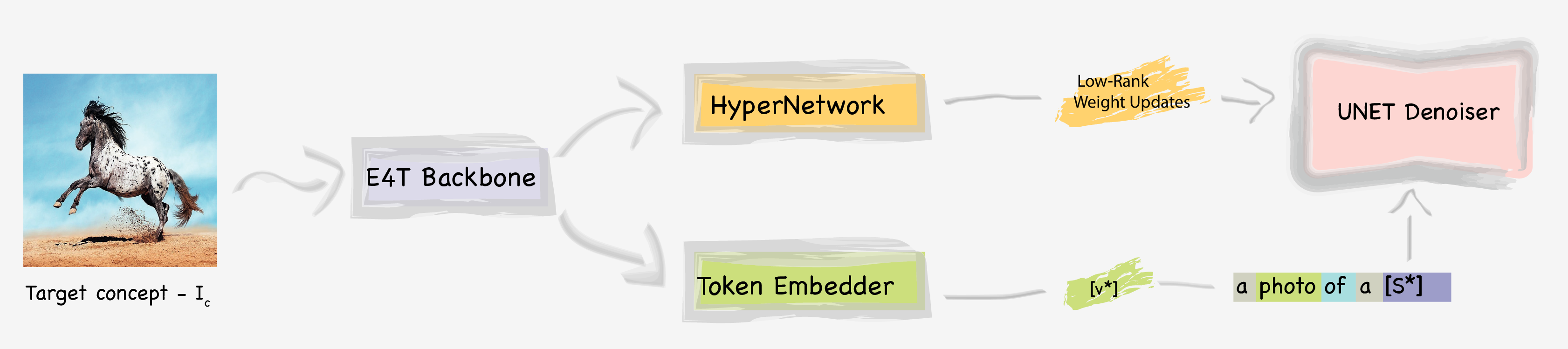
We pre-train an encoder to predict word-embeddings and Low-Rank weight updates. Our method consists of a feature-extraction backbone which follows the E4T approach and uses a mix of CLIP-features from the concept image, and denoiser-based features from the current noisy generation. These features are fed into an embedding prediction head, and a hypernetwork which predicts LoRA-style attention-weight offsets. During inference, we predict LoRA weights and word-embedding and tune those on the target subject.
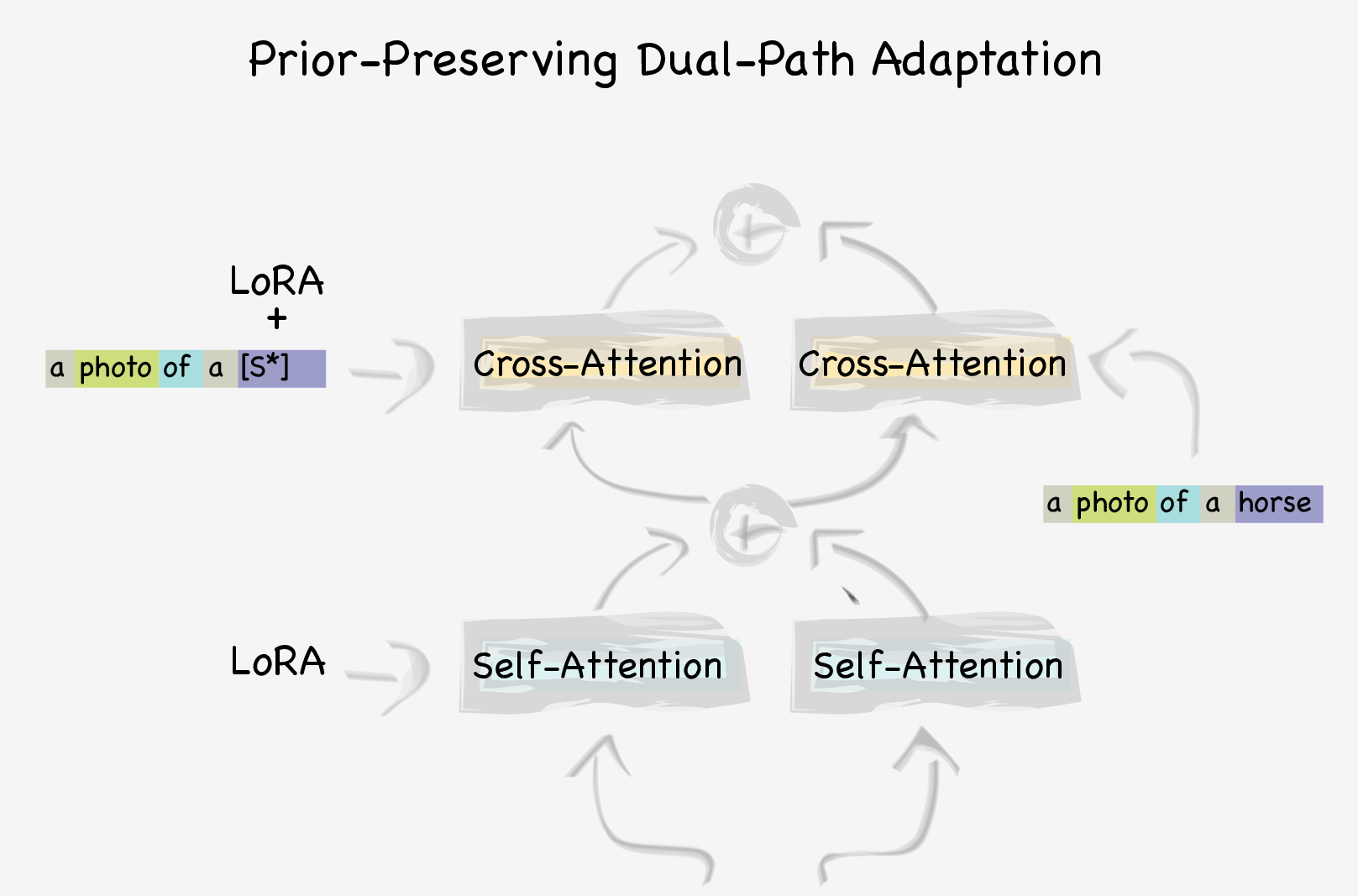
Avoiding subject overfitting via dual-path adaptation: We employ a dual-path adaptation approach where each attention branch is repeated twice, once using the soft-embedding and the hypernetwork offsets, and once with the vanilla model and a hard-prompt containing the embedding's nearest neighbor. These branches are linearly blended to better preserve the prior. The latter path preserves the model's prior, while the new adapted branch adapts to the target concept.
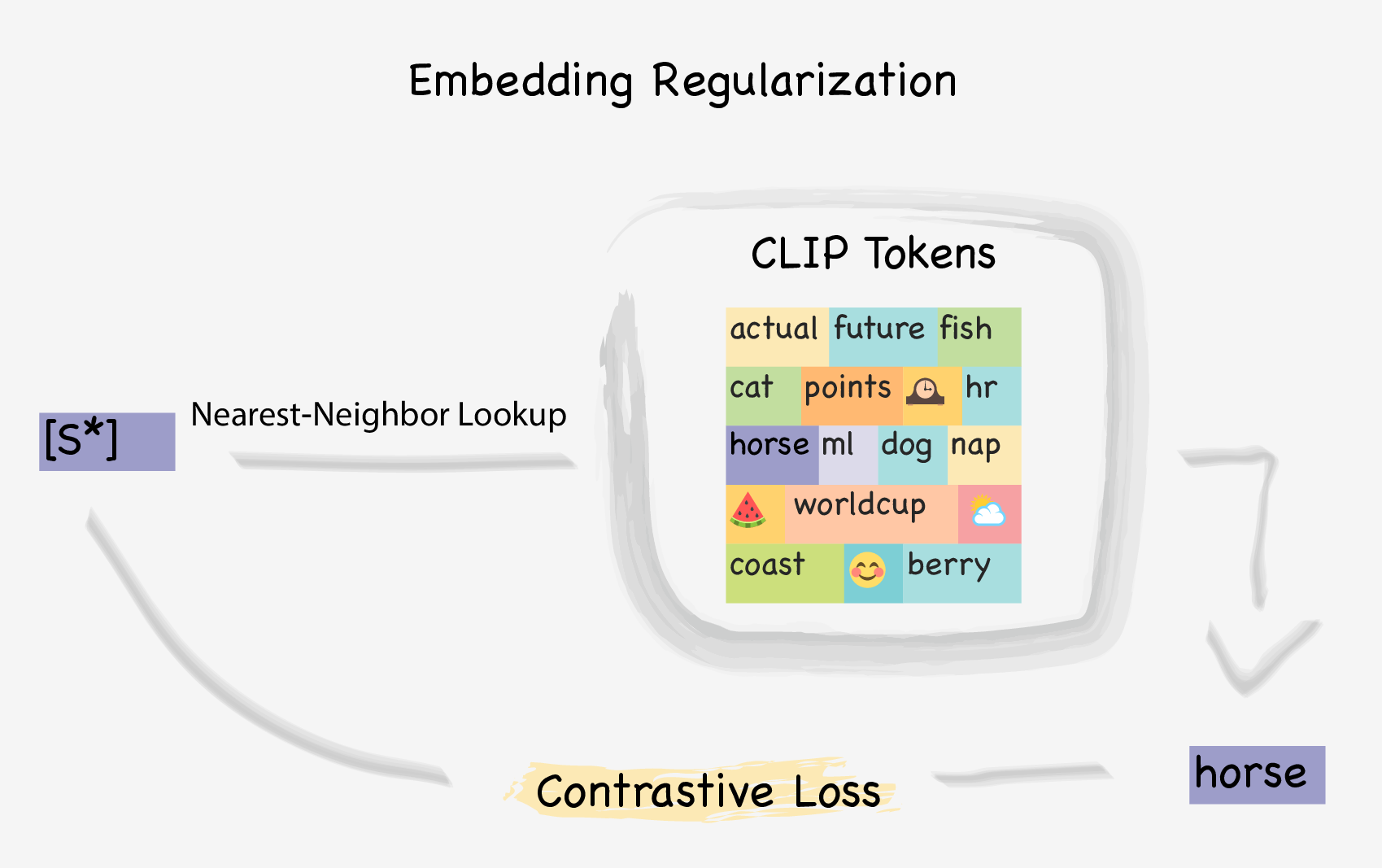
Push predictions towards CLIP word embeddings for better editability: Our embeddings are regularized using a nearest-neighbor-based contrastive loss that pushes them toward real words but away from the embeddings of other concepts. Intuitively, staying close to the real-word embedding manifold ensures the target embedding will blend well in novel prompts, preserving the prompt semantic.

Qualitative comparison with existing methods. Our method achieves comparable quality to the state-of-the-art using only a single image and 12 or fewer training steps. Notably, it generalizes to unique objects which recent encoder-based methods struggle with.
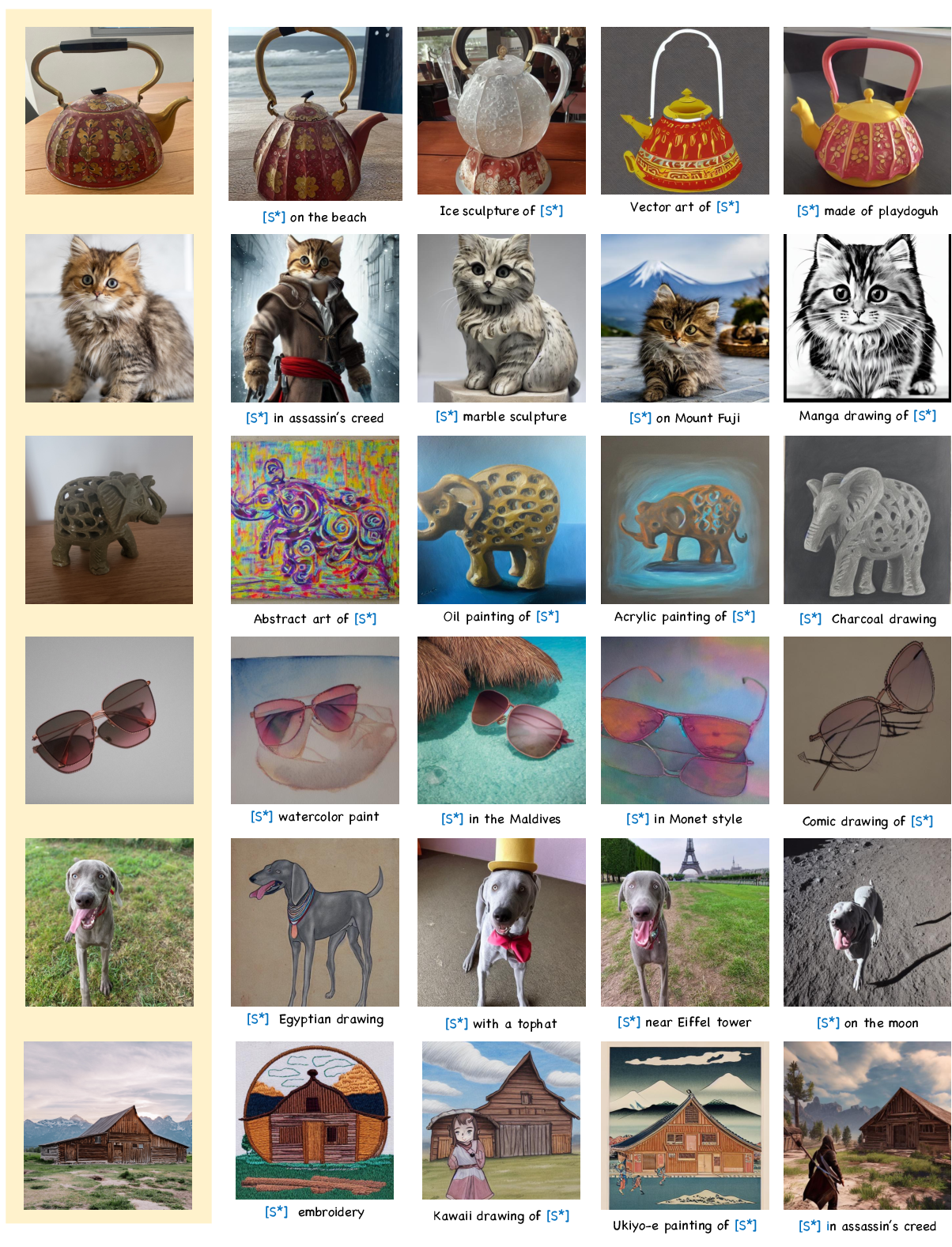
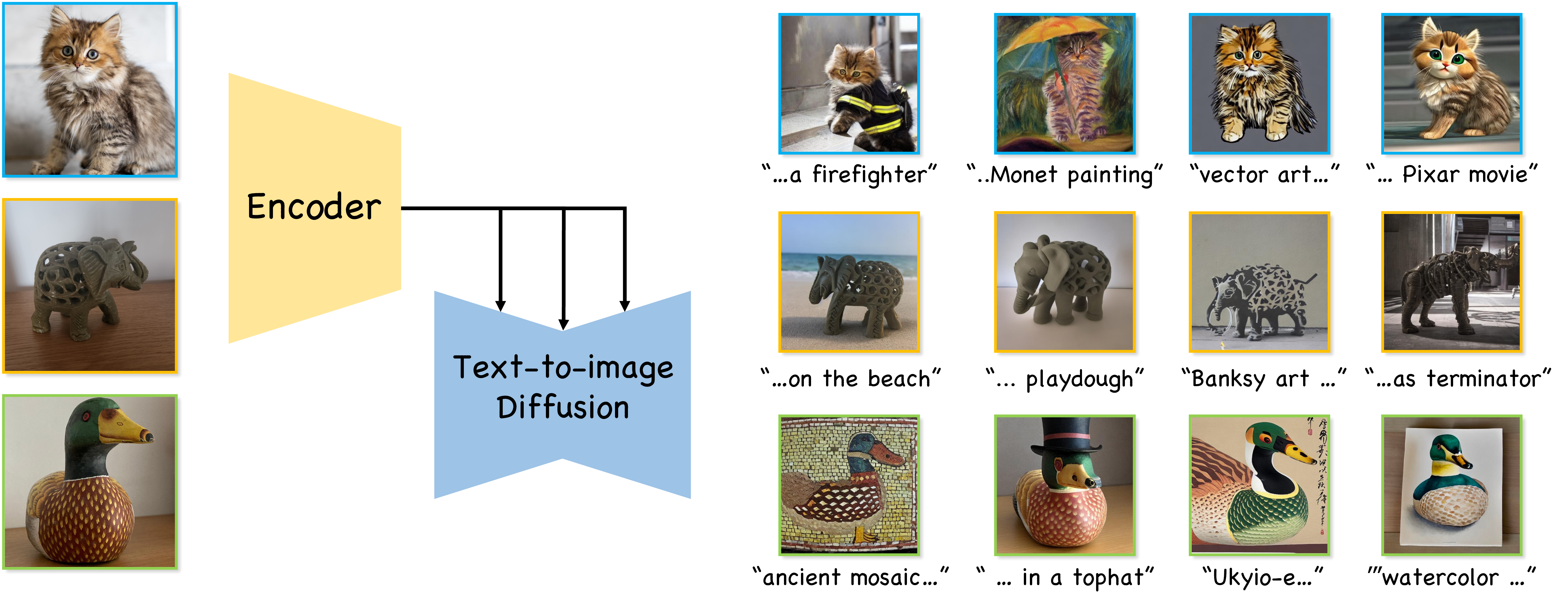
Additional qualitative results generated using our method. The left-most column shows the input image, followed by 4 personalized generations for each subject.